03
Phase by phase
Phase 1 — Requirements (5 min). Distinguish functional from non-functional. Functional: what the system does (users post, followers see posts). Non-functional: how well it does it (latency < 200ms, 99.9% availability, read-heavy 100:1). Always ask "who are the users, how many, where?" — location matters for CDN and replication. Don't ask about every conceivable feature — pick 3–4 core flows.
Phase 2 — Scale estimation (5 min). Derive numbers from assumptions. "100M DAU × 2 posts/user/day = 200M posts/day ÷ 86400s ≈ 2300 writes/sec. Reads are 100× that = 230k reads/sec. Each post is ~1KB → 200GB/day → 70TB/year." The numbers drive the design: 230k reads/sec means CDN and cache at minimum. 70TB/year means sharding matters.
Phase 3 — High-level design (15 min). Sketch one box diagram: clients → LB → API → cache → DB → queue → workers. Label what each piece does. Establish the single-user baseline first, then layer in distributed concerns. Define the API (5–6 endpoints with request/response shapes). Pick a database and justify the choice in one line: "Postgres because we need transactions on the payments table."
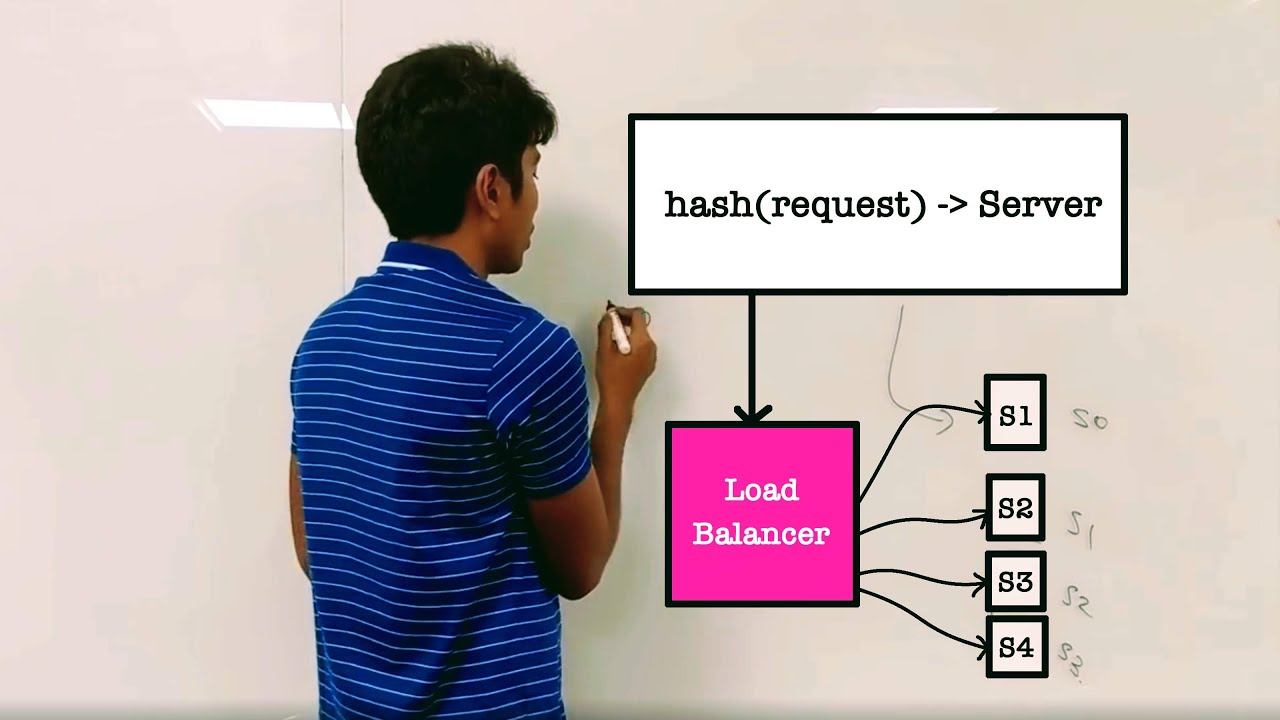
Phase 4 — Deep dive (20 min). Pick the one interesting thing in your design and go deep. For Twitter, it's fan-out. For Uber, it's geospatial indexing. For a URL shortener, it's hashing. Don't go deep on everything — pick the concept uniquely interesting to this problem and explore its tradeoffs, failure modes, and alternatives. This is where you prove you're senior.