05
Deep dive — what actually scales horizontally
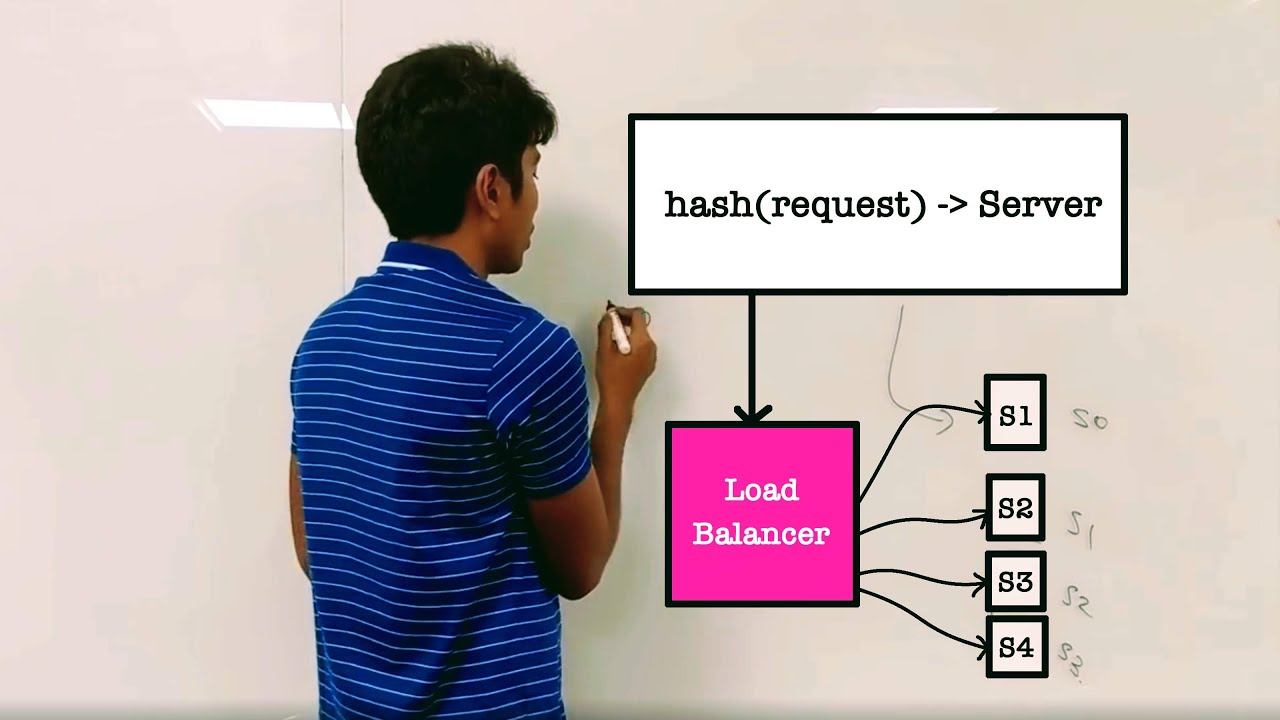
Horizontal scaling is trivial for stateless services, excruciating for stateful ones. "Stateless" means every request can be answered by any instance with no knowledge of prior requests from that client. Any state (sessions, counters, cached results) lives outside the service — in Redis, the DB, or a JWT the client carries.
Stateful services that don't scale horizontally for free: relational databases (one writer at a time; read replicas help reads but writes need sharding), in-memory session stores (move to Redis), file uploads sitting on local disk (move to object storage), WebSocket connections (sticky sessions + a pub/sub fabric).
The stateless checklist — if any answer is "yes," you have work before horizontal scaling works:
- Does the app read or write files on local disk? → move to S3 / EFS.
- Does it store sessions in process memory? → move to Redis.
- Does it cache computed results per-process? → either fine (soft cache) or move to shared cache.
- Does it hold open WebSocket / SSE connections? → introduce a pub/sub for cross-server message delivery.
- Does it assume singleton jobs (e.g., a cron)? → introduce distributed locking so only one instance runs the job.